Spring Boot 멀티모듈 프로젝트 - 1. 프로젝트 구성, 킥오프
왜 스프링인가요?
지금 프로젝트가 순항 중인 상태에서 솔직히 아차싶은 부분이다. 평소 서비스 개발에 프레임워크가 중요하다고 생각하는 편은 아니다. 프로젝트의 규모와 예상되는 적당한 미래에 따라 의존성과 기술을 잘 선택만 하면 된다고 생각하고 있다.
지금의 트래픽들을 생각해봤을 땐 (Ktor, Koin, Exposed)로 코루틴의 이점을 가져가봐도 좋다고 생각하고, 여전히 과반수 이상의 조직 엔지니어가 python을 주로 사용하거나 사용할 줄 알기 때문에 fastAPI가 또 좋은 선택지가 될 수 있었을 거라 생각한다.
스프링을 선택할 땐, 솔직한 이야기로 채용이 제일 큰 이유라고 생각했다. 그렇지만, 코틀린 엔지니어 채용도 쉬운 일은 아니었다. 아직도 같이할 백엔드 엔지니어들을 다 찾지 못한 상태다. 본인 전 직장 CTO님의 블로그 글 “스타트업 채용, 정말 언어 문제일까요?”라는 글을 읽고 정말 공감되고 있다.
멀티 모듈을 왜 쓰려고 하나요?
첫 번째, 멀티 모듈 구조를 사용하려고 하는 새 프로젝트는 이미 한국에서 성과가 꽤 있는 프로덕트의 해외 진출을 목표로 시작되었다. 이미 조직에 많은 도메인 전문가 (PO, PD, …)가 서포트하고 있는 중이기 때문에, 해당 비지니스 로직을 이해하고 고도화시키는데 큰 어려움은 없다고 볼 수 있었다.
두 번째로는 조직이 목적 조직의 형태를 갖고 있었기 때문이다. 물론 스쿼드 형태의 목적조직이 엄격하게 분리된 도메인을 다루는 건 아니지만, 확장의 준비의 의미도 있었다.
세 번째로는 지금 확장을 위한 국가 외에 추가적인 확장의 가능성이다.
스쿼드가 이미 “글로벌"이라는 키워드를 갖고 있었기 때문에 같은 모듈이더라도 Pluggable하게 구현하여 어플리케이션을 조립할 때 쉽게 새로운 API가 나올 수 있도록 하고자 하는 의도도 있다.
이와 같은 내용은 모두 README.md 에 담아두었다.
프로젝트 구조
이 전에, Gradle의 의존성 정의에 대한 설명을 하자면,
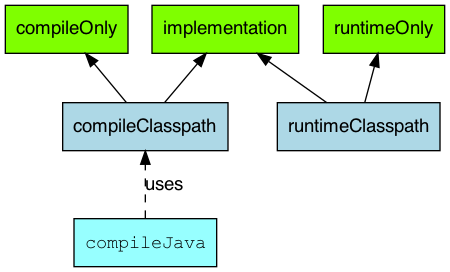
- RuntimeOnly : Runtime only dependencies. 컴파일 시점에서는 필요하지 않지만, 실행 시점에서는 필요한 의존을 정의할 때 사용한다.
- CompileOnly: Compile time only dependencies, not used at runtime. 컴파일 시점에만 필요한 라이브러리의 경우를 사용한다.
- Implementation: Implementation only dependencies. 의존이 컴파일 및 런타임에서 모두 필요한 경우 사용한다. 프로젝트 빌드 시점에서 해당 의존을 컴파일에도 사용하고 빌드된 결과물에도 포함된다.
큰 형태의 Gradle 구조를 그려보았다. 해당 아키텍쳐를 구성할 때, 토스ㅣSLASH 22 - 지속 성장 가능한 코드를 만들어가는 방법을 많이 참고하였다.
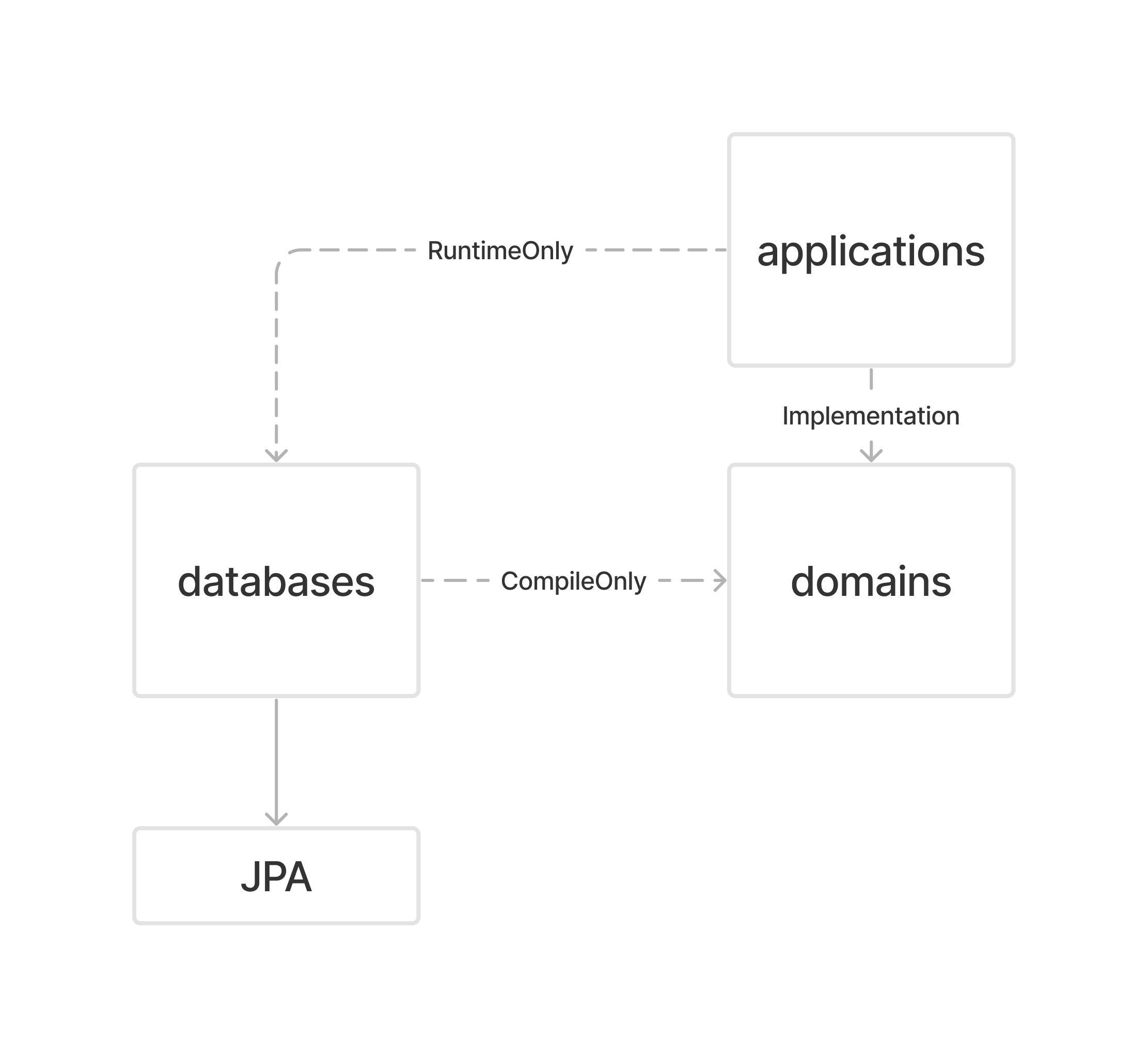
이렇게 구성함으로써, domains:* 모듈들은 database의 기술과 구현에 대한 내용을 모르게 된다.
도메인 모듈은 아래와 같은 구성을 하고 있다.
":domain:a"
+--- models
+--- repositories
+--- services
\--- exceptions
Repository
Repository는 도메인 모듈 안에서 인터페이스로 정의되어 있다. 실제 구현은 도메인 레이어의 모듈이 아니라, 데이터 레이어에 해당하는 storages-mysql-core 모듈에서 실제 구현이 일어난다. CompileOnly로 참조하고 있기 때문에 인터페이스를 구현할 수 있다.
그리고 정의된 테이블의 스키마 (Entity)들도 마찬가지로 데이터 레이어에 포함되어 있다.
도메인 레이어에 있는 레포지토리 인터페이스는…
@Repository
interface UserAuthorizationRepository {
fun findUserByUserId(userId: Long): AuthorizedUser?
}
이렇게 정의되어 있어서 JPA를 이용하는건지 아무 것도 알 수 없다.
storages-mysql-core 모듈의 Repository 구현은 아래와 같다.
@Repository
internal class UserAuthorizationRepositoryImpl(
private val userJpaRepository: UserJpaRepository,
) : UserAuthorizationRepository {
override fun findUserByUserId(userId: Long): AuthorizedUser? {
val user = userJpaRepository.findById(userId).orElse(null) ?: return null
return AuthorizedUser.toAuthorizedUser(user)
}
}
하위 레이어를 탐색해야 JpaRepository라는 구현 정보를 확인할 수 있다.
언제든 데이터베이스를 교체하거나 확장할 수 있도록 염두해둔 구조다.
Database 형상 관리
 작은 규모의 엔지니어 조직이라 아직 DBA같은 인원이 없다.
그러므로 신뢰성 있는 도구로 안전하게 구성해야 한다.
흔히들 사용하는 GitOps 워크플로우에서 사용할
작은 규모의 엔지니어 조직이라 아직 DBA같은 인원이 없다.
그러므로 신뢰성 있는 도구로 안전하게 구성해야 한다.
흔히들 사용하는 GitOps 워크플로우에서 사용할 core-tool이라는 유틸성 어플리케이션을 조립해두었다. (core-api의 유틸성 어플리케이션이라는 뜻…)
그리고 flyway는 이 어플리케이션만 사용할 수 있도록 아래와 같이 의존성을 구성해 두었다.
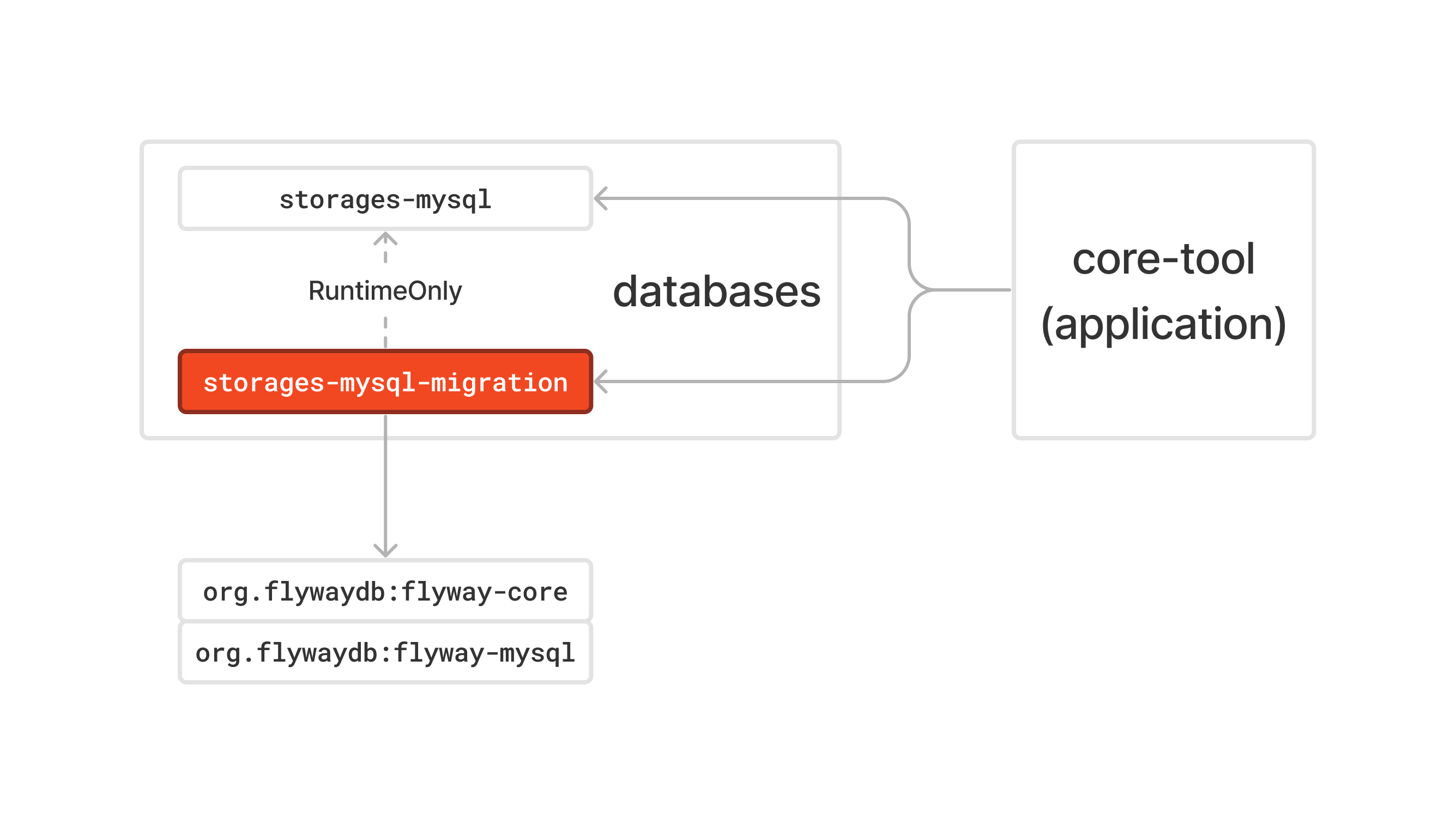
다른 어플리케이션은 storages-mysql-migration을 의존하지 않는다. 즉, core-tool만 의존하게 되어 의도하지 않은 flyway의 동작 자체를 막아두었다.
일반 어플리케이션은 실행 시 데이터베이스의 정합성이 중요하기 때문에, hibernate의 ddl-auto를 아래와 같이 세팅하였다.
spring:
jpa:
hibernate:
ddl-auto: validate
이렇게 되면 데이터베이스가 완전히 마이그레이션되기 전에 앱이 실행되어 배포가 실패되는 일을 막을 수 있을 거라 생각한다. 서비스는 쿠버네티스 클러스터 위에서 실행되고 있다. 그러므로 Replica Set이 생성되기 전에 꼭 성공해야하는 Job으로 정의해두었다. 구현은 아래와 같다.
@Order(1)
@Component
class MigrationRunner : CommandLineRunner {
@Autowired
private val flyway: Flyway? = null
var logger: Logger = LoggerFactory.getLogger(MigrationRunner::class.java)
override fun run(vararg args: String?) {
if (args.isEmpty()) {
return
}
if (args[0] == "migrate") {
logger.info("Migrating database...")
flyway!!.migrate()
}
}
}
테스트
단위 테스트에서는 일반적으로 스프링 컨텍스트를 사용하는 경우를 사용하지 않는 방향을 갖고 있다. 테스트가 느려질 뿐더러 모든 Bean을 일일히 다 생성해서 갖고 있을 이유는 없다. Kotest를 주로 사용하고 있고, 테스트 코드를 쓰는데 참고하고 있는 글은 아래와 같다.