aws DynamoDB의 Single-table Design 적용
Single-table Design이 필요한 이유
조인 (JOIN)
dynamoDB는 관계형 데이터베이스에서 흔히 쓰이는 조인을 지원하지 않는다. 정규화된 테이블 간의 조인은 이해하기 쉽고 편리하지만, 실제로는 많은 비용을 발생시킨다. 만약 같은 방식으로 dynamoDB를 접근한다면 순차적으로 데이터를 가져오는 방식으로 구현해야 할 것이다. 데이터의 정합성 역시 의심할 수 밖에 없는 결과를 가져온다.
상품과 상품 옵션을 가져온다고 가정하자.
1. productId로 상품을 Product 테이블에서 가져온다.
2. productId로 상품 옵션을 ProductOption 테이블에서 가져온다.
이미 2번의 조회 쿼리가 발생했고, 다른 테이블에서 각각 조회한 데이터를 어셈블하는 형태가 된다.
하지만 DynamoDB의 구조적 장점 덕분에, 이러한 데이터를 하나의 테이블에 모두 저장할 수 있다. 서비스의 요구사항을 정리하고 쿼리 계획을 잘 정리해두면 데이터 모델을 디자인하는데 매우 큰 도움이 된다. (설계는 “DynamoDB Data Modeler”의 도움을 받았다.)
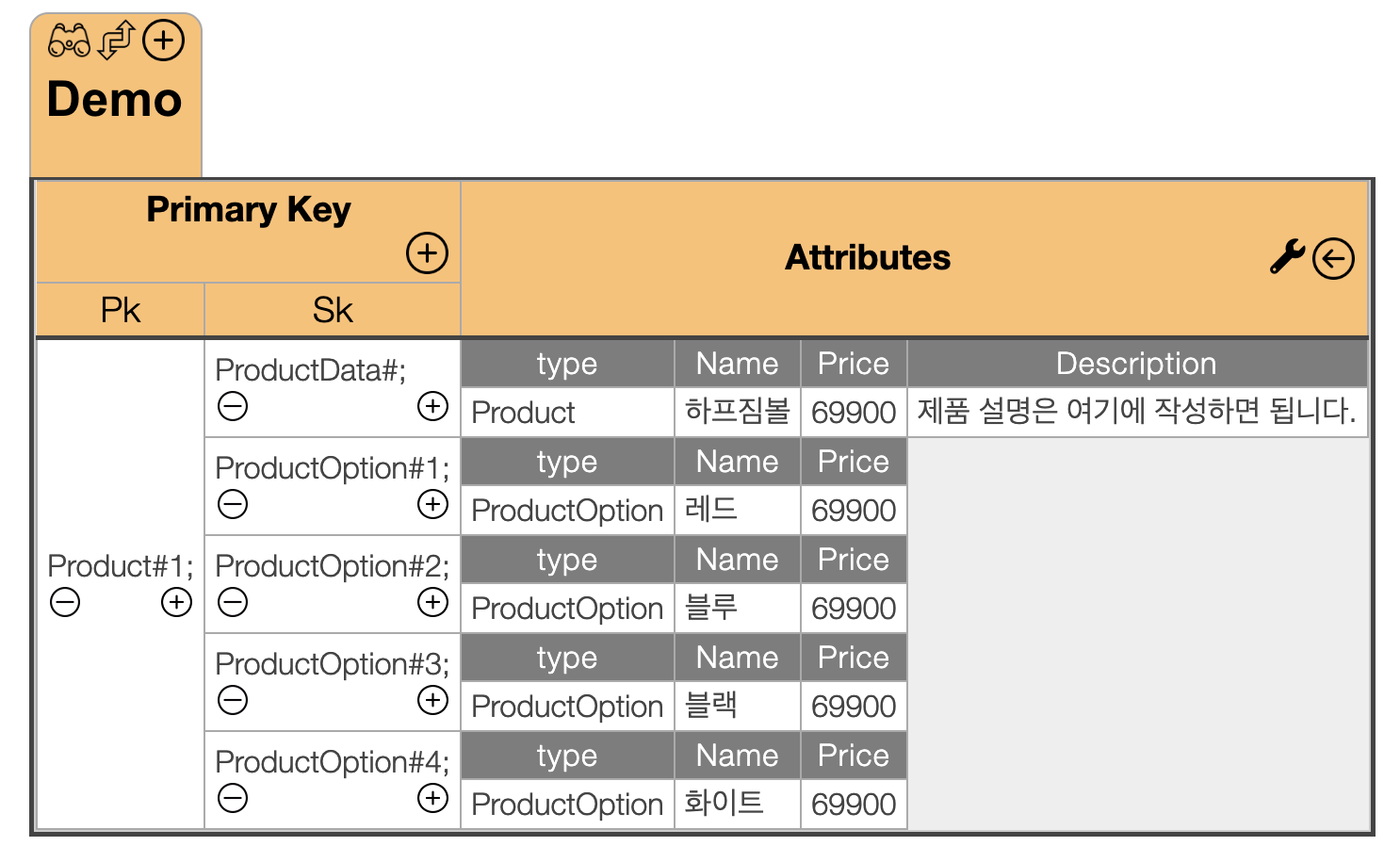
이렇게 데이터를 저장해두었다고 하자. 조회는 아주 간단해진다.
aws dynamodb query \
--table-name Product \
--key-condition-expression "Pk = :pk" \
--expression-attribute-values '{":pk": {"S": "Product#1;"}}'
테이블 1개 위에서 요구사항에 맞는 적당히 최적화된 설계를 잘 해두면, 매우 빠른 속도를 얻을 수 있다.
비용
위에서 든 예시 처럼, 속성에 따라 Sort Key 빌드 전략을 다르게 가져가면, 읽기 쿼리를 최적화할 수 있다. 역정규화(Denormalization)된 많은 데이터들이 하나의 문서에 모두 저장시킬 것 같은 NoSQL 데이터베이스이기 때문에 읽기 비용을 꽤 낭비할 것 같지만, 그렇지 않게 설계하여 최적화할 수 있다.
특히 Provisioned 과금 정책을 이용했을 때, RCU/WCU를 단 1개의 테이블에서만 관리할 수 있기 때문에 얻을 수 있는 비용 절약도 있다. 1개의 테이블에서만 RCU/WCU를 관리하기 때문에 모니터링 및 운영 비용도 당연히 줄게 된다.
설계와 구현 이후 운영 중에 새로운 접근 패턴이 생겼을 때, 현재 설계된 스키마로 해결되지 않는 경우가 생길 수 있다. 하지만 Single-table design은 개인적으로는 거의 Best practice처럼 느껴지는 중이다.
PynamoDB의 다형성 디자인을 지원하기 위한 기능
aws lambda와 API Gateway로 구성된 API 어플리케이션을 구성 중이었고, Python을 쓸 계획이었기 때문에 PynamoDB를 선택했다.
class BaseTable(Model):
class Meta:
table_name = "some-service-table"
pk = UnicodeAttribute(hash_key=True, attr_name="Pk")
sk = UnicodeAttribute(range_key=True, attr_name="Sk")
gsi1_pk = UnicodeAttribute(attr_name="GSI1Pk", null=True)
gsi1_sk = UnicodeAttribute(attr_name="GSI1Sk", null=True)
discriminator = DiscriminatorAttribute(attr_name="Type")
ttl = UTCDateTimeAttribute(null=True, default=default_ttl)
created_at = UTCDateTimeAttribute(default_for_new=datetime.now())
updated_at = UTCDateTimeAttribute(default=datetime.now())
여기서 discriminator는 다형성을 지원하기 위한 필드이다.
설계 섹션에서 언급한 모델에 대응하는 Type이라는 컬럼을 자동으로 추가해주는데, 해당 문서가 어떤 타입인지를 구분하기 위한 필드이다.
class Product(BaseTable, discriminator="Product"):
name = UnicodeAttribute()
price = NumberAttribute()
description = UnicodeAttribute()
@staticmethod
def build_pk(product_id: int) -> str:
return f"Product#{product_id};"
@staticmethod
def build_sk() -> str:
return f"ProductData#;"
@classmethod
def new(cls, product_id: int, name: str, price: int, description: str) -> Self:
return cls(
pk=cls.build_pk(product_id),
sk=cls.build_sk(),
name=name,
price=price,
description=description,
)
class ProductOption(BaseTable, discriminator="ProductOption"):
name = UnicodeAttribute()
price = NumberAttribute()
@staticmethod
def build_pk(product_id: int) -> str:
return f"Product#{product_id};"
@staticmethod
def build_sk(product_option_id: int) -> str:
return "ProductOption#{product_option_id}"
@classmethod
def new(cls, product_id: int, product_option_id: int, name: str, price: int) -> Self:
return cls(
pk=cls.build_pk(product_id),
sk=cls.build_sk(product_option_id),
name=name,
price=price,
)
이렇게 테이블 1개를 사용하되 Product와 ProductOption에 대한 정보를 저장하고 읽어올 수 있다.
Reference
아래의 re:invent 영상이 구현과 운영에 많은 도움이 되었다.